FlatBuffers
This is a summary of a talk I gave at the React Vancouver meetup in September 2019.
Streak (where I work) is a CRM platform for Gmail, and as such deals with a lot of data. Like, way more than I expected. All this data — much of which gets loaded into the browser all at once — leads to slow network requests, slow deserialization, and high memory usage. In other words, a crummy user experience. To make matters worse, the hardest hit are our most valuable customers with the largest datasets.
FlatBuffers To The Rescue
One technology we use to combat this is FlatBuffers, an “efficient cross platform serialization library”. It was created at Google for game development, where you need to squeeze out every ounce of performance. It’s not limited to game engines though and can be used anywhere you need optimized data serialization.
How it works is right in the name. Flat = the ability to access hierarchical data without parsing; Buffer = binary representation. You store your data in a binary blob and you get random access to any part of the underlying data structures.
Libraries exist for all the major languages — JavaScript, C#, Python, Go, etc. There’s even one for a language called Lobster which I had never heard of but which looks cool.
Of course, binary serialization is nothing new, and there are tons of alternatives: Protocol Buffers, MessagePack, Thrift, Avro.1 All of them beat the pants off plaintext formats like JSON when it comes to metrics like request payload size. Where FlatBuffers stands apart is that it requires no deserialization step when reading data.
Rather than parsing the FlatBuffer-encoded file into an intermediate representation and loading that into memory, you use fancy table lookups to determine where your property is located then read the bytes at the given offset. This wiki entry dishes out the nitty gritty details of how this works. No deserialization means your memory usage stays low and you waste no CPU cycles extracting your data.
Here’s official benchmarks showing that FlatBuffers are indeed fast. My own benchmarks are unscientific and unrigorous, but for a ~1.3 MB JSON document the request size was halved and the deserialization time cut to a third (there is of course still some overhead when reading). In any case, speedier than old tortoise JSON.
Let’s Use This Thing
FlatBuffers has its own Interface Definition Language with tables (objects), vectors (lists), numbers, booleans, and strings. Squint hard enough and it looks like C.
// item.fbs
table Item {
contacts: [Contact];
isStarred: bool;
}
table Contact {
name: string;
email: string;
}
root_type Item;
A schemaless version also exists if strong typing isn’t your bag.
Compile the schema file to use in the language of your choice using flatc.
flatc --js item.fbs
The result is unreadable (and even gnarlier for other languages), but you should have no need to touch the generated code.2
// item_generated.js
...
Item.prototype.isStarred = function() {
var offset = this.bb.__offset(this.bb_pos, 8);
return offset ? !!this.bb.readInt8(this.bb_pos + offset) : false;
};
...
Here’s what ingesting a serialized binary blob might look like using the FlatBuffers JavaScript library and the module we generated.
import flatbuffers from './flatbuffers.js';
import { Item } from './item_generated.js';
async function readContacts() {
const response = await fetch('/item.bin');
const buffer = await response.arrayBuffer();
const bytes = new Uint8Array(buffer);
const bb = new flatbuffers.ByteBuffer(bytes);
const item = Item.getRootAsItem(bb);
for (let i = 0; i < item.contactsLength(); i++) {
const contact = item.contacts(i);
console.log('Contact:', contact.name());
}
}
Not too bad right? Only a few lines more than hitting an ordinary JSON API.
Worthwhile?
FlatBuffers work well for Streak. The performance gains vastly improve the user experience. But it’s only one performance optimization, not the whole solution, and there are many downsides.
It’s unfamiliar technology for one. Prior to joining Streak I had used Thrift and Protocol Buffers, but FlatBuffers hadn’t crossed my radar. Binary formats add developer friction and FlatBuffers are no exception. Inspect a binary response in Chrome DevTools and you’ll see something that looks like this:
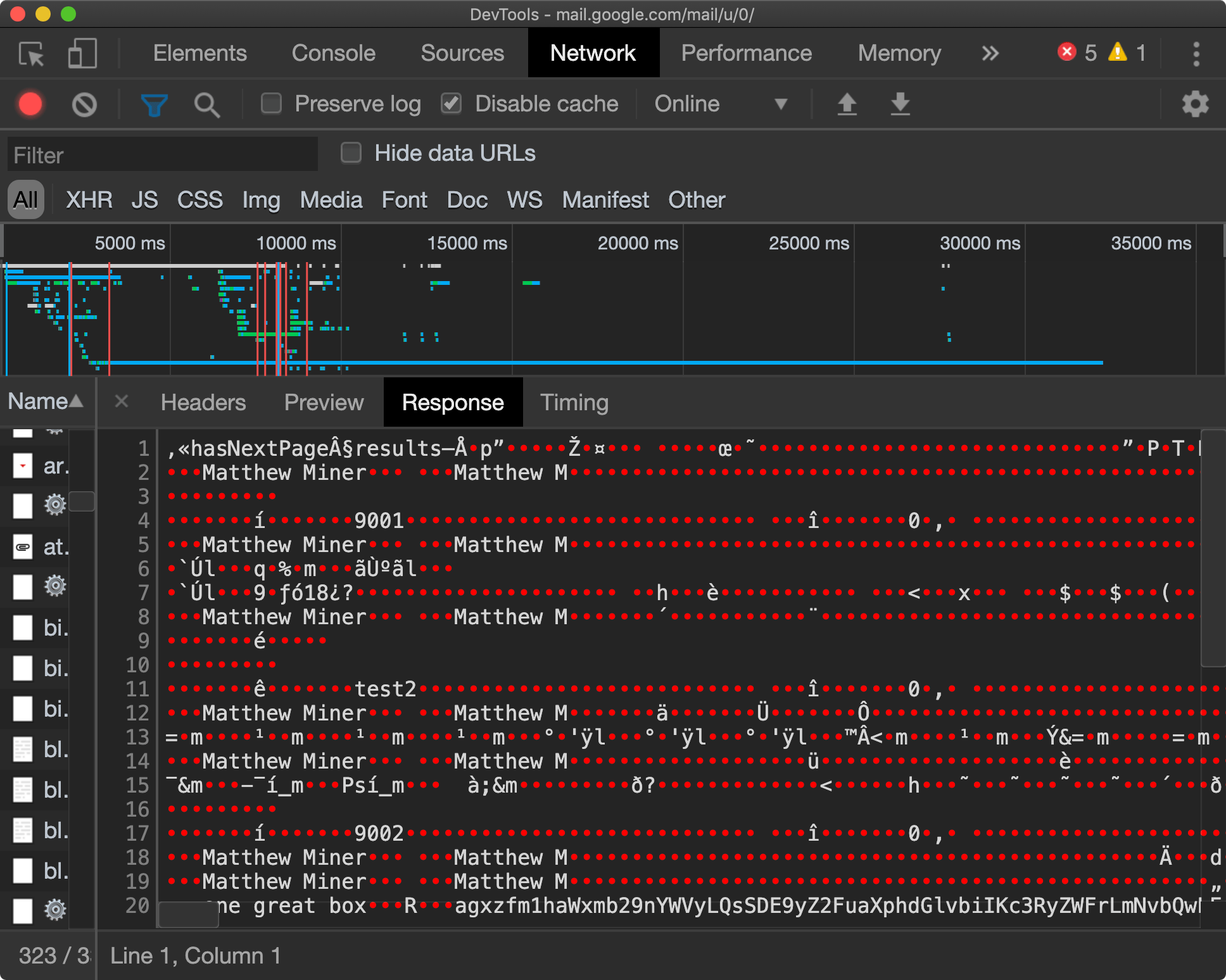
There are workarounds — you can serve JSON in your development environment and FlatBuffers in production — but it’s complexity you previously didn’t have.
Whether you should use FlatBuffers depends on your app. Are request size and deserialization bottlenecks? For many web apps this won’t be true, e.g. a TODO app where you might expect a few hundred or thousand items at most.
The usual advice for any optimization applies: measure first. Slowness that FlatBuffers could alleviate might point to a deeper issue that you’re papering over. Perhaps you load too much data at once that could instead be delivered in small chunks as needed. If you have a mobile app, halving your request size might still blow through your user’s monthly limits. It might be time to rethink your architecture.
For the right ailment though, FlatBuffers might be the tonic you need.